


Hinweis: Am Anfang wollte ich das für die Flashcards testen, bin aber dann auf die Dialog Cards umgestiegen. Leider habe ich dabei vergessen an manchen Stellen den Namen des Inhaltstypen zu ändern. Also bitte nicht irritieren lassen!
- Wie gehe ich vor?
Damit das alles klappt werden unterschiedliche Programme und Vorbereitungen benötigt.
Natürlich einen H5P-Editor für die Erstellung der H5P-Vorlage mit der ersten Dialog Card
- Wo finde ich überall H5P-Editoren?
Natürlich bietet die ZUM e.V. einen unter https://apps.zum.de/ an.
Eine ganz tolle Desktop-Version gibt es unter https://lumi.education/de/lumi-h5p-desktop-editor/
Zum Testen und Spiel: https://einstiegh5p.de/
oder natürlich im LMS, wie Moodle
- Python auf dem Rechner installieren
Hier gibt es immer die aktuellsten Versionen: https://www.python.org/downloads/
- Einen Zielordner anlegen
Es gibt nichts digital persönlicheres als die Logik einer Ordnerstruktur. Kurz um, einen Ordner am passenden Ort anlegen.
- Zielordner befüllen und Skript ausführen
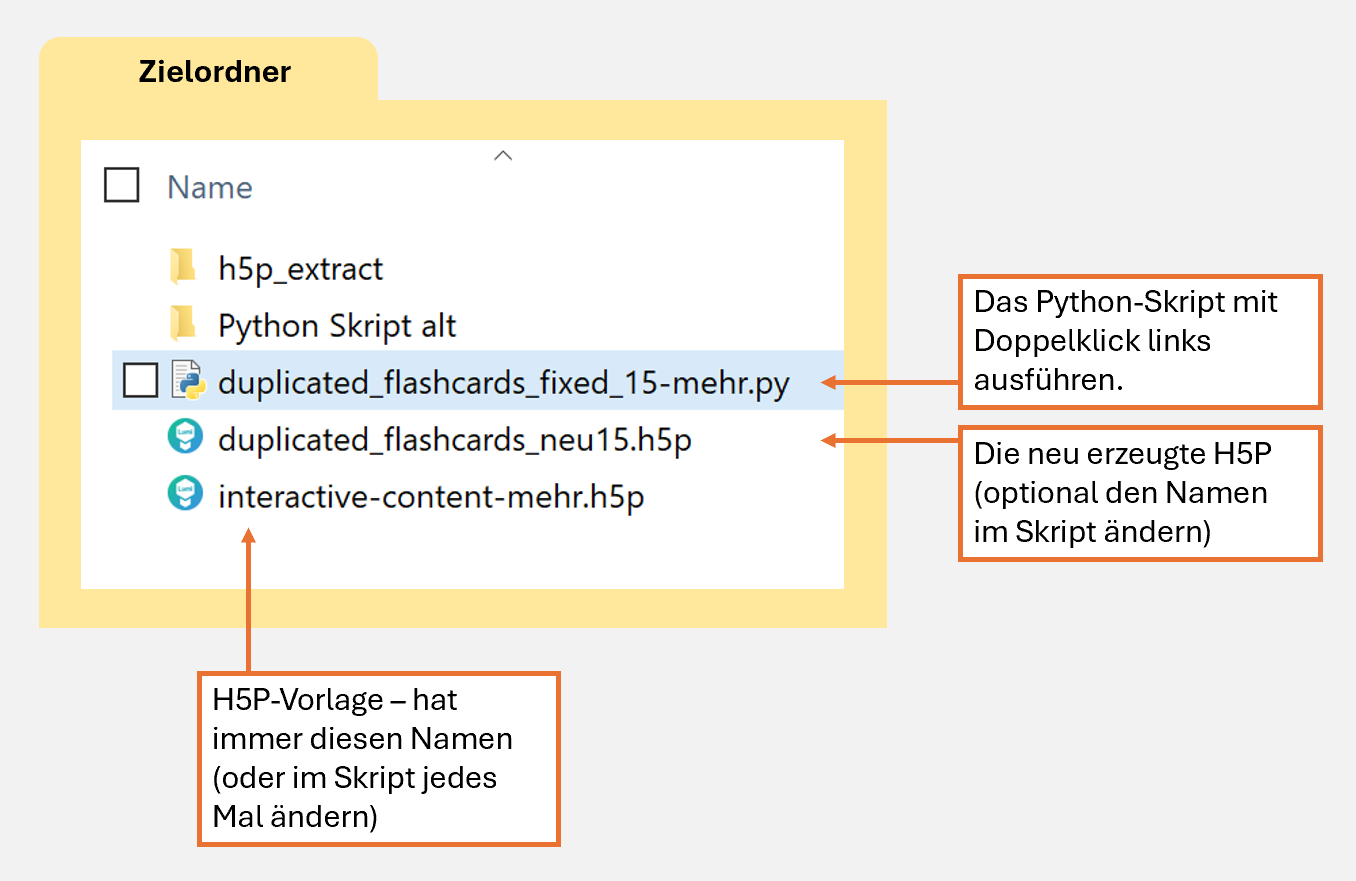
Damit das Skript auch funktioniert, muss jetzt der Ordner passend befüllt werden.
Woher bekomme ich das Skript? Siehe weiter unten: Kopie des Skripts erstellen
Wichtig: Es müssen das Python-Skript und die H5P-Vorlage drin sein. Doppelklick auf das Skript und fertig!
Kopie des Skripts erstellen
Kopie der Skript-Vorlage (siehe unten) in einen Texteditor einfügen.
Speichern unter wählen und die Endung .py hinzufügen.
import zipfile import json import os import shutil # Funktion zum Vervielfältigen der Flashcards def duplicate_flashcards(content_data, num_duplicates=15): original_card = content_data['dialogs'][0] # Originale Karte for i in range(num_duplicates): # Dupliziere die Karte new_card = original_card.copy() new_card['text'] = f'<p style="text-align: center;"><strong>Vorderseite {i+2}</strong></p>\n' new_card['answer'] = f'<p style="text-align: center;">Rückseite {i+2}</p>\n' content_data['dialogs'].append(new_card) return content_data # Pfade zur Original-H5P-Datei und zum Extraktionsort h5p_file_path = 'interactive-content-mehr.h5p' extract_path = 'h5p_extract/' # Extrahiere die H5P-Datei with zipfile.ZipFile(h5p_file_path, 'r') as zip_ref: zip_ref.extractall(extract_path) # Pfad zur content.json und Bilderordner content_json_path = os.path.join(extract_path, 'content', 'content.json') with open(content_json_path, 'r', encoding='utf-8') as json_file: content_data = json.load(json_file) # Flashcards vervielfältigen (z.B. 15 mal) updated_content_data = duplicate_flashcards(content_data, num_duplicates=15) # Speichere die aktualisierte content.json with open(content_json_path, 'w', encoding='utf-8') as json_file: json.dump(updated_content_data, json_file, ensure_ascii=False, indent=4) # Nur die erlaubten Dateien (JSON, Bilder) in die neue H5P-Datei packen def zipdir(path, ziph): # Gehe durch alle Dateien und füge nur zulässige Dateitypen hinzu allowed_extensions = ['.json', '.png', '.jpg', '.jpeg', '.gif', '.bmp', '.tif', '.tiff', '.svg', '.eot', '.ttf', '.woff', '.woff2', '.otf', '.webm', '.mp4', '.ogg', '.mp3', '.m4a', '.txt', '.pdf', '.rtf', '.doc', '.docx', '.xls', '.xlsx', '.ppt', '.pptx', '.odt', '.ods', '.odp', '.xml', '.csv', '.diff', '.patch', '.swf', '.md', '.textile', '.wav', '.gltf', '.glb'] for root, dirs, files in os.walk(path): for file in files: if any(file.endswith(ext) for ext in allowed_extensions): file_path = os.path.join(root, file) ziph.write(file_path, os.path.relpath(file_path, path)) # ZIP die erlaubten Dateien in eine neue H5P-Datei output_h5p_file = 'duplicated_flashcards_neu15.h5p' with zipfile.ZipFile(output_h5p_file, 'w') as zipf: zipdir(extract_path, zipf) print(f'H5P-Datei erstellt: {output_h5p_file}')
Wie geht das, auch wenn ich keine Ahnung von Programmieren habe?
Einen Eindruck bekommt man HIER
- 117 Aufrufe